- Full-service marketing bureau sinds 2008
- Premier partner Google, Shopify & Facebook partner
- Nr 2 - Fonk 150 best agencies 2025
- Partner in groei, samen succesvoller
- Strategie
 Breng het gedrag van je klanten in kaart. Ontdek knelpunten, optimaliseer je funnels en verhoog je conversie.Krijg strategisch voordeel met een concurrentie-analyse. Ontdek waar je concurrenten staan en hoe jij ze slim voorbijgaat.Ontdek of jouw aanbod echt past bij je doelgroep. Wij helpen je naar een ijzersterke product-market fitBouw een sterk merk met een duidelijke strategie. Van positionering tot visuele identiteit.
Breng het gedrag van je klanten in kaart. Ontdek knelpunten, optimaliseer je funnels en verhoog je conversie.Krijg strategisch voordeel met een concurrentie-analyse. Ontdek waar je concurrenten staan en hoe jij ze slim voorbijgaat.Ontdek of jouw aanbod echt past bij je doelgroep. Wij helpen je naar een ijzersterke product-market fitBouw een sterk merk met een duidelijke strategie. Van positionering tot visuele identiteit. - Online marketingLinkbuilding is het actief links vergaren van andere websites naar jouw website Beter ranken & meer bezoekersMet conversie optimalisatie (CRO) maak je van jouw bezoekers klanten. Wil jij jouw conversieratio verhogen?Een nieuw product promoten, event lanceren, rebranding doorvoeren of inspelen op de seizoenen?Wil jij verleidelijke website teksten laten schrijven? En goed geoptimaliseerde SEO teksten laten schrijven?Op basis van het projectplan maakt de professionele fotograaf de juiste foto's. Zo wordt jouw website of promotie goed in beeld in gebracht!Wil je meer leads & meer omzet? TriplePro is de growth hacking agency voor groei via growth strategy & marketing.
- Website
- Cases
- Over ons
- Contact
Wat is robots.txt?
Een robots.txt bestand is een tekstbestand op je website waarin je aangeeft welke gedeeltes van je website webcrawlers niet mogen bezoeken en crawlen. Het is een manier om te communiceren met de robots van de zoekmachines, zoals Google.
Waarvoor dient de robots.txt?
Voordat een crawler je website bezoekt, kijkt deze eerst of er een robots.txt bestand aanwezig is. Deze geeft echter geen volledige garantie dat de crawler het tekstbestand ook daadwerkelijk opvolgt. Het robots.txt bestand dient namelijk als instructie. In de meeste gevallen worden de instructies echter wel opgevolgd.
Waarom is de robots.txt belangrijk?
Met behulp van de robots.txt geef je aan welke pagina's van je website niet gecrawld hoeven te worden. Doe je dit niet, dan betekent dit dat de hele website wordt gecrawld, dus ook pagina's waarbij die niet de bedoeling is. Je crawl budget (het aantal pagina's dat Google dagelijks kan crawlen) wordt dan besteed aan het crawlen van pagina's die niet in de zoekresultaten terecht horen, wat je natuurlijk wilt voorkomen. Je hoeft je echter pas zorgen te maken over je crawl budget als je een hele grote website hebt met duizenden pagina's.
Waarvoor dient de robots.txt?
Voordat een crawler je website bezoekt, kijkt deze eerst of er een robots.txt bestand aanwezig is. Deze geeft echter geen volledige garantie dat de crawler het tekstbestand ook daadwerkelijk opvolgt. Het robots.txt bestand dient namelijk als instructie. In de meeste gevallen worden de instructies echter wel opgevolgd.
Waarom is de robots.txt belangrijk?
Met behulp van de robots.txt geef je aan welke pagina's van je website niet gecrawld hoeven te worden. Doe je dit niet, dan betekent dit dat de hele website wordt gecrawld, dus ook pagina's waarbij die niet de bedoeling is. Je crawl budget (het aantal pagina's dat Google dagelijks kan crawlen) wordt dan besteed aan het crawlen van pagina's die niet in de zoekresultaten terecht horen, wat je natuurlijk wilt voorkomen. Je hoeft je echter pas zorgen te maken over je crawl budget als je een hele grote website hebt met duizenden pagina's.
Hoe ziet een robots.txt bestand eruit?
Hieronder zie je een voorbeeld van een robots.txt bestand van één van onze klanten:
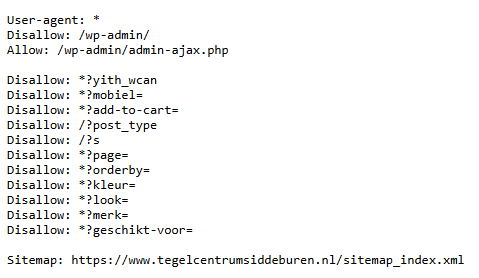
De robots.txt bevat altijd de volgende elementen:
User-agent
De user agent kun je zien als de specifieke crawler waaraan je instructies geeft. Dit kan bijvoorbeeld de bot van Google zijn of die van Bing. Wat je invult achter ‘user-agent’ bepaalt dus voor welke zoekmachine de daaropvolgende regels gelden. Met een sterretje (*) geef je aan dat de regels gelden voor alle crawlers en dus ook alle zoekmachines.
Allow en Disallow:
Met de instructies 'allow' en 'disallow' geef je aan welke pagina's of URL's er wel of niet gecrawld mogen worden. De meeste robots.txt bestanden bevatten standaard een aantal URL's die worden gedisallowed. Een voorbeeld hiervan is je inlogpagina. Deze hoeft natuurlijk niet in de zoekresultaten te verschijnen en dus ook niet te worden gecrawld. Heb je webshop? Dan heb je waarschijnlijk veel categoriefilters en zoekfilters die ervoor zorgen dat er allerlei extra URL's met parameters worden gecreëerd. Het is verstandig deze uit te sluiten van de crawling, omdat deze voor duplicate content zorgen en een hap nemen uit je crawl budget. Als we bovenstaande afbeelding als voorbeeld pakken, dan worden deze URL's waarvan de slug begint met onderstaande tekens uitgesloten:
- /?s
- /?post_type
Dit geldt ook voor alle URL's die ergens in de URL het volgende bevatten:
- ?yith_wcan
- ?page=
- ?kleur=
De volgorde van de regels in het robots.txt bestand is belangrijk. Zo is de eerste regel altijd leidend.
Daarnaast zijn er enkele wildcards die door zoekmachines worden ondersteund en helpen het robots.txt bestand op te stellen:
- *
Met dit symbool blokkeer je meerdere reeksen. Als je bijvoorbeeld een filter wilt uitsluiten, hoef je met deze wildcard niet alle URL's handmatig in het bestand te zetten. Kijk je naar het eerdergenoemde voorbeeld, dan worden dus alle URL's die ?page= bevatten uitgesloten.
- $
Met deze wildcard geef je aan dat alle URL's die eindigen op een bepaalde tekenreeks niet moeten worden gecrawld. Wil je bijvoorbeeld PDF-bestanden uitsluiten? Zet dan de regel 'Disallow: .pdf$' in je robots.txt bestand. Op deze manier worden alle URL's die eindigen op .pdf uitgesloten.
XML-sitemap
In de robots.txt dient ook een link te staan naar je XML-sitemap. Hiermee voorzie je zoekmachines een handig overzicht van alle pagina's die je website bevat, wat ze helpt bij het crawlen.
Je robotst.txt bestand testen
Wil je zeker weten dat je jouw robots.txt bestand op de correcte manier hebt opgesteld? Met deze tool kun je hem testen: https://rankmath.com/tools/robots-txt/
Laat ons je helpen met je robots.txt bestand
Let op! Wees voorzichtig met het maken van aanpassingen aan de robots.txt. Een kleine fout kan namelijk al funest zijn en ervoor zorgen dat een groot deel van je website niet meer gecrawld wordt. Laat dit dus het liefst aan specialisten over die hier genoeg kennis over hebben. Twijfel je of je het goed aanpakt? Neem dan contact op met één van onze technische SEO-specialisten. Zij helpen je graag verder.

Begin vandaag met
jouw succesverhaal
Diensten
BrandingSEO uitbestedenGoogle Ads uitbestedenLinkbuilding uitbestedenSociale media marketingFacebook marketing uitbestedenLinkedIn marketing uitbestedenPinterest marketing uitbestedenSnapchat marketing uitbestedenWhatsApp marketing uitbestedenTikTok marketing uitbestedenInstagram marketing uitbestedenCopywritingConversie optimalisatieE-mailmarketingFotografieKennisdeling
BlogsInternet marketing kennisbankMarketing modellenOnline marketing metrics & kpi'sNeuromarketing in PraktijkWat is Google Ads?Hoger komen in Google?Social media campagne opzetten?Wordpress webshop laten maken?Wordpress website laten maken?Online marketing tips 2026SEO tips 2026Subsidie Digitalisering DrentheKantoor Groningen
Griffeweg 97
9723 DV Groningen
Of neem contact op
| 050 305 00 23 | |
| info@triplepro.nl | |
| support@triplepro.nl |
Groningen
Website laten maken GroningenWebshop laten maken GroningenE-mailmarketing GroningenSEO bureau GroningenGoogle Ads bureau GroningenLinkbuilding GroningenSocial media bureau Groningen







